
High-Performance Computing (HPC) for Management Science
Our primary research resource is the 'customer database'. Given the size of these data warehouses (including tables with customer transactions with several TBs of data per company) we often use high-performance supercomputing equipment to analyze these data using statistical methods or data mining techniques.
Given our high need for supercomputing capabilities, we have been lead users of the VSC (Flemish Supercomputer Center). This enables us to be part of the premier league at the forefront of technology.
Three major projects are using high-performance computing facilities:
DIMAROPT: Direct Marketing Optimization
Determining optimal customer segment composition while maximizing overall customer life-time value has been the overall objective for most marketing management activities. Trying to achieve this goal without proper marketing/predictive analytics support almost certainly will result in suboptimal decision making.
Our innovative approach has been published in:
JONKER J.J., PIERSMA N. & VAN DEN POEL D. (2004), Joint Optimization of Customer Segmentation and Marketing Policy to Maximize Long-Term Profitability, Expert Systems with Applications, 27 (2), 159-168.
In the figure below an overview of the approach is shown. It immediately reveals why HPC capabilities are necessary to make it feasible, i.e., results have to be bootstrapped to obtain stable results (transition probabilities between large state spaces result in sparse matrices, which is not desirable). Please read the paper for a more detailed description.
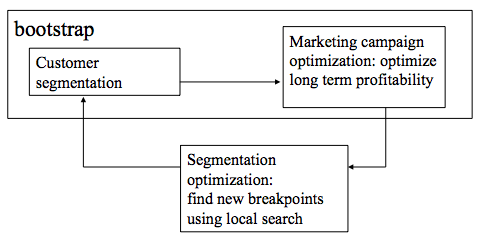
The availability of supercomputers enable us to go way beyond this initial approach.
Recent results have been presented at the NIPS 2010 MLOAD workshop in Whistler (Canada).
SHANAHAN J. & VAN DEN POEL D. (2010), Determining optimal advertisement frequency capping policy via Markov decision processes to maximize click through rates, MLOAD 2010 NIPS Workshop, Whistler.
Current status of this project
Using existing code bases in JAVA, we have been able to compile a suite of HPC job scripts that allow us to run large systems to push the boundaries of what is currently feasible.
Combination of Marketing and Logistics
For the home-vending division of Belgian Icecream Group (B.I.G. nv) with its well-known brand 'IJSBOERKE' we develop a novel application. They face the challenge (similar to many other companies) of reconciling marketing and sales with logisitics. They have to visit their customers in order to realize a sale, but it is uncertain whether customers actually buy something.
In technical terms, we solve a multiple traveling salesmen problem (m-TSP) with stochastic demand and time windows. This means that we have to determine the optimal routing of more than 150 salesreps throughout Belgium (this is the 'multiple' aspect); salesreps start their routes every day at home, visit a pre-determined set of customers, and go back home (or to the depot for re-supply) (This is the TSP aspect); some of their customers have to be visited in specific time slots (e.g. some shopping streets are only open for supply until 11 a.m.); demand is stochastic, i.e. non-deterministic so the company does not know whether (nor which products) customers will buy.
This application has been developed in Matlab. Currently, the multiple TSP part scales up to about 24 parallel processes, the single TSP part scales up to whatever number of salesreps one needs (because it is also embarrassingly parallel).
Current status of this project
We finalized a first code base. A first 'live' run has been performed, which will be implemented in the field the coming weeks. We still need to work on optimizing the work flow with a better integration of the HPC facilities. Currently, the HPC part is limited to running single TSPs in parallel. This will be improved upon as a next version of the software is released.
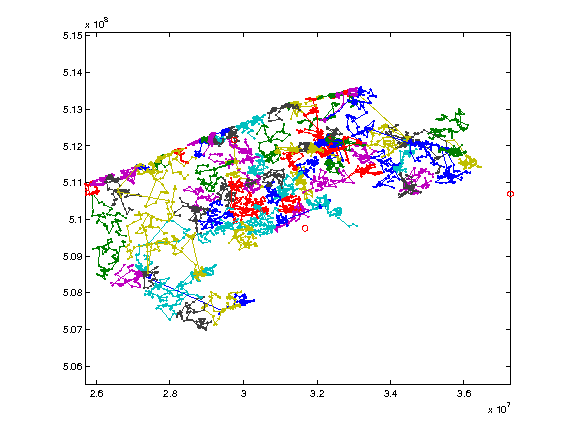
In the Figure below, an intermediate result of the optimization process is shown (with 106 routes) for the coastal region of Belgium.
Random Multinomial Logit: RMNL
Several years ago, Anita Prinzie and Dirk Van den Poel developed a new technique to improve the predictive accuracy of multinomial classification.
PRINZIE Anita & VAN DEN POEL Dirk (2008), Random Forests for Multiclass classification: Random Multinomial Logit, Expert Systems with Applications, 34 (3), 1721-1732.
The original code was written in SAS/SAS macro's. Later we moved to JAVA. The results of the analyses are stored in a database. Initially, we used Oracle, but as this is not supported on our HPC, we moved to the PostgreSQL open-source database.
Current status of this project
Given the embarrassingly parallel nature of the algorithm, we developed an HPC implementation of the algorithm in collaboration with our good colleague Prof. Jean-Jacques De Clercq (HoGent, University College Ghent). Again, in 2011, we carry out a student project to finalize the HPC implementation of entire system. Below, the pictures shows the 2011 project team (from right to left: Prof. Jean-Jacques De Clercq, Prof. Dr. Dirk Van den Poel and the two HoGent students).

Supercomputing events/conferences
Blog entry of SC10 in New Orleans, LA (November 19, 2010)
Participation at the VSC launch event (March 23, 2009).